Welcome to our blog, "Exploring the Wonders of Computer Engineering," dedicated to all computer engineering students and enthusiasts! Join us on an exciting journey as we delve into the fascinating world of computer engineering, uncovering the latest advancements, trends, and insights.
# **Components of Relational Databases: A Comprehensive Guide**
In the vast landscape of data management, **relational databases** stand out as a fundamental framework for organizing and managing data. Let's delve into the intricacies of these databases, exploring their components, significance, and advantages over other database types.
## **1. Introduction**
When we think of databases, we envision structured repositories of information. Relational databases take this concept further by organizing data into **rows and columns**, forming tables where data points are related to each other. Here's what you need to know:
### **What Is a Relational Database?**
- A **relational database**:
- Organizes data into tables.
- Uses **SQL queries** to combine data from multiple tables.
- Empowers organizations to gain insights, optimize workflows, and identify opportunities.
## **2. Key Components of Relational Databases**
Let's explore the essential components:
### **a. Tables**
- **Tables** are the building blocks.
- Each table represents an individual dataset.
- Example: A sales database might have tables for customers, orders, and products.
### **b. Records (Rows)**
- **Records** correspond to individual data entries within a table.
- In our sales example, each record could represent a specific customer, order, or product.
### **c. Fields (Columns)**
- **Fields** define data attributes within a table.
- **Schemas** define logical organization, ensuring consistency and data integrity.
- Schema example: Relationships between tables (e.g., linking customer records to orders).
### **e. Keys**
- **Primary keys** uniquely identify records within a table.
- **Foreign keys** establish relationships between tables.
- Example: Customer ID as a common key across customer and order tables.
## **3. ACID Properties**
Relational databases adhere to ACID properties for reliable transactions:
- **Atomicity**: All changes are performed as a single operation.
- **Consistency**: Data remains consistent from start to finish.
- **Isolation**: Intermediate states of transactions are not visible to others.
- **Durability**: Changes persist even after system failures.
## **4. Real-World Examples**
- Imagine a bank transfer: Withdrawal and deposit as a single transaction.
- Sales reports by industry or company using customer and transaction tables.
## **5. Conclusion**
Relational databases empower efficient data management, reporting, and decision-making. Whether tracking orders, managing inventory, or analyzing sales, these components form the backbone of modern data systems.
## **Tags**
Data Science, Databases, Relational Databases, SQL, Database Management
Module 1: Introduction & Entity Relationship (ER) Model
Introduction to Database Management Systems (DBMS): A DBMS is software that interacts with users, applications, and the database itself to capture and analyze data. It allows users to create, read, update and delete data in a database.
Characteristics of Database Systems: Some key characteristics include support for ACID properties (Atomicity, Consistency, Isolation, Durability), data abstraction, support for multiple views of data, and security mechanisms.
Database Users: There are several types of database users including database administrators, database designers, end-users, and application programmers.
Types of Data:
Structured Data: Highly-organized and formatted in a way so it’s easily searchable in relational databases.
Semi-structured Data: A type of data where both raw and organized data are present. It is not as raw as unstructured data and not as organized as structured data.
Unstructured Data: Information that either does not have a pre-defined data model or is not organized in a pre-defined manner. Unstructured information is typically text-heavy but may contain data such as dates, numbers, and facts.
Data Models and Schema: A data model is an abstract model that organizes elements of data and standardizes how they relate to one another and to the properties of real-world entities. A schema, in a relational database, is a collection of database objects, including tables.
Three Schema Architecture: The three-schema architecture separates the conceptual, external, and internal schemas, promoting data abstraction.
Database Languages and Architectures: Database languages are used to read, update and store data in a database. There are several types such as DDL, DML, DCL and TCL. Database architectures define how data is stored, processed and accessed.
Entity Relationship (ER) Model: The ER model defines the conceptual view of a database. It works around real-world entities and the associations among them.
Basic Concepts: Includes entities, attributes, relationships, constraints, etc.
Entity Sets & Attributes: An entity set is a collection of similar entities. Attributes are the properties that define the entity.
Relationships and Constraints: Relationships are the associations between entities. Constraints are the rules enforced on entities.
Cardinality and Participation: Cardinality defines the number of entities in one entity set, which can be associated with the number of entities of other sets via a relationship set. Participation constraint determines the minimum number of relationship instances that an entity can participate in.
Weak Entities: A weak entity is an entity that cannot exist in a database unless another type of entity also exists in that database. Weak entity types have a primary key that is partially or totally derived from the parent entity in the relationship.
Relationships of Degree 3: Also known as ternary relationships, they involve three entities.
Module 2: Relational Model
Structure of Relational Databases: A relational database is a type of database that stores and provides access to data points that are related to one another. It consists of a set of tables with data that fits into a predefined category.
Integrity Constraints: Integrity constraints ensure that changes made to the database by authorized users do not result in a loss of data consistency. Thus, integrity constraints prevent the entry of inconsistent data into the database.
Synthesizing ER Diagram to Relational Schema: This process involves converting entities into tables, converting relationships into foreign keys, etc.
Relational Algebra: It is a procedural query language, which takes instances of relations as input and yields instances of relations as output. It uses operators to perform queries.
Select, Project, Cartesian Product Operations: These are basic operations in relational algebra. Select operation selects tuples that satisfy a given predicate. Project operation returns its argument relation, removing duplicate tuples and sorting the result. Cartesian product operation combines information from any two relations into a single relation.
Joins: Equi-join, Natural Join: Joins combine rows from two or more tables based on a related column between them. Equi-join is a join with a join predicate containing only equality comparisons. Natural join is a type of equi-join where the join predicate arises implicitly by comparing all columns in both tables that have the same column names.
Structured Query Language (SQL): SQL is a standard language for managing and manipulating databases.
Data Definition Language (DDL): DDL is a subset of SQL, used to define and manage all the objects in an SQL database.
Table Definitions and Operations: In SQL, tables are used to store data. Table definitions include defining a table and its columns and data types. Table operations include the SQL commands like SELECT, INSERT, UPDATE, DELETE, etc.
Module 3: SQL DML (Data Manipulation Language), Physical Data Organization
SQL DML: DML is a subset of SQL, used to add, update and delete data in a database.
Queries on Single and Multiple Tables: SQL queries can be used to retrieve data from a single table or multiple tables.
Nested Queries: A nested query is a query within another SQL query which retrieves data from one table based on data from another table.
Aggregation and Grouping: SQL provides several functions, like COUNT, SUM, AVG, MAX, MIN, that can be used to perform an operation on a data set. The GROUP BY statement groups rows that have the same values in specified columns into aggregated data.
Views, Assertions, Triggers: A view is a virtual table based on the result-set of an SQL statement. An assertion is a predicate expressing a condition that we wish the database to always satisfy. Triggers are stored programs, which are automatically executed or fired when some events occur.
SQL Data Types: Each column in a database table is required to have a name and a data type. SQL offers several data types to choose from, depending on the need to store numbers, characters, or boolean values.
Physical Data Organization: It refers to the technique of designing efficient structures for storing data files on the disks.
Review of Terms: Includes terms like records, fields, tables, etc.
Heap Files, Indexing: A heap file allows record retrieval by examining each record for matching criteria. Indexing is a data structure technique to efficiently retrieve records from the database files based on some attributes on which the indexing has been done.
B-Trees & B±Trees: B-Tree and B+ Tree : They are the tree data structures used for external storage systems. B-Tree is used when the data is stored in the disk it reduces the number of input/output operations. B+ Tree is used when the data is stored in the main memory of the computer system.
Extendible Hashing: It is a type of hash system which treats a hash as a bit string, and uses a trie for bucket lookup.
Indexing on Multiple Keys: It is a way of sorting data using multiple keys.
Module 4: Normalization
Introduction to Normalization: Normalization is a method to remove all these anomalies and bring the database to a consistent state.
Functional Dependency: Functional dependency is a constraint between two sets of attributes in a relation from a database.
Armstrong’s Axioms: Armstrong’s axioms are a set of axioms (or, more precisely, inference rules) used to infer all the functional dependencies on a relational database.
First, Second, Third, and Boyce Codd Normal Forms: These are rules to define the minimum requirements for a relational database design. They are progressive, meaning that the first normal form must be met before moving to the second, the second before the third, and so on.
Lossless Join and Dependency Preserving Decomposition: Lossless join property is a fundamental property that guarantees that the spurious tuple generation does not occur with respect to relation instances. Dependency preserving decomposition is a decomposition of the database schema D such that for each functional dependency X -> Y specified on relation schema R in D, where X and Y are both subsets of R, there is a relation schema Q in the decomposition such that (X U Y) is a subset of Q.
Module 5: Transactions, Concurrency and Recovery, Recent Topics
Transaction Processing Concepts: A transaction is a single logical unit of work that accesses and possibly modifies the contents of a database.
Concurrency Control: Concurrency control is a database management systems (DBMS) concept that is used to address conflicts with the simultaneous accessing or altering of data that can occur with a multi-user system.
Recovery: Database recovery is the process of restoring the database back to the correct state.
NoSQL Databases: NoSQL databases are purpose-built for specific data models and have flexible schemas for building modern applications.
Key-value DB: Key-value databases are a type of NoSQL database where each value is associated with a unique key.
Document DB: Document databases make it easier for developers to store and query data in a database by using the same document-model format they use in their application code.
Column-Family DB: A column-family database is a type of NoSQL database that uses a column-family data model. This model is a type of wide-column store, which uses tables, rows, and columns, but unlike a relational database, the names and format of the columns can vary from row to row in the same table.
Graph DB: A graph database is a type of NoSQL database that uses graph theory to store, map and query relationships.
Each module provides a structured approach to understanding different aspects of database management systems, progressing from
Let’s dive into the fundamental concepts of computer networks:
1. Network
A network is a collection of interconnected devices (nodes) that communicate with each other. It can be as small as two computers or as large as a global network connecting billions of devices. Networks enable data exchange and resource sharing.
2. Node
A node is a point of intersection/connection within a network. It represents a device (such as a computer, printer, or router) that participates in data communication. Nodes can be physical (hardware) or logical (software).
!Node
3. Network Topology
Network topology defines the structure of a network by specifying how nodes are interconnected. There are various types of network topologies:
Bus Topology: All nodes are connected to a single backbone cable.
Ring Topology: Nodes form a closed loop.
Star Topology: All nodes connect to a central hub or switch.
Mesh Topology: Every node is directly connected to every other node.
Tree Topology: Combines bus and star topologies.
Hybrid Topology: A mix of different topologies.
!Network Topologies
4. Routers
A router is a networking device that forwards data packets between computer networks. It connects different networks and allows devices to share an Internet connection. Routers operate at the Network Layer (Layer 3) of the OSI model.
!Router
5. OSI Reference Model
The OSI (Open Systems Interconnection) model is a conceptual framework that standardizes network communication. It consists of seven layers, each with specific functions:
Physical Layer: Handles physical connections and bit synchronization.
Data Link Layer: Ensures error-free data transfer between nodes.
Network Layer: Manages routing and addressing.
Transport Layer: Provides end-to-end communication and flow control.
Session Layer: Establishes, maintains, and terminates sessions.
Presentation Layer: Translates data formats and provides encryption.
Application Layer: Supports user applications (e.g., HTTP, FTP).
!OSI Model
6. Difference Between Hub, Switch, and Router
Hub: Connects devices in a single collision domain (Layer 1).
Switch: Filters and forwards data based on MAC addresses (Layer 2).
Router: Routes data between different networks (Layer 3).
7. TCP/IP Model
The TCP/IP model is a practical implementation of networking protocols. It includes four layers: Application, Transport, Internet, and Network Access.
8. TCP and UDP
TCP (Transmission Control Protocol): Reliable, connection-oriented communication.
Network Security: Safeguarding Your Digital Landscape
In an interconnected world, network security is paramount. Whether you’re a seasoned IT professional or a curious learner, understanding the intricacies of network security is essential. In this blog post, we’ll explore key concepts, tools, and best practices to fortify your digital landscape.
1. Security Threats and Vulnerabilities
Vulnerabilities: The Achilles’ Heel
What are vulnerabilities?
Vulnerabilities are weaknesses, flaws, or shortcomings in systems, software, or processes.
Types of vulnerabilities:
Technical vulnerabilities: Bugs in code, hardware errors, or misconfigurations.
Human vulnerabilities: Employees falling for phishing attacks or other common pitfalls.
The issue arises when vulnerabilities remain undiscovered or unaddressed, making them susceptible to attacks.
Threats: The Dark Forces
What are threats?
Threats are malicious or negative events that exploit vulnerabilities.
Examples of threats:
Malware (viruses, worms, Trojans).
Unauthorized access attempts.
Denial-of-service (DoS) attacks.
Threats can compromise confidentiality, integrity, and availability.
Risk: Balancing Act
What is risk?
Risk is the potential for loss or damage when threats exploit vulnerabilities.
Risk assessment involves evaluating the likelihood and impact of threats.
Effective risk management balances security measures with business needs.
2. Firewall and Intrusion Detection Systems (IDS)
Firewalls: The Gatekeepers
Firewalls limit network access based on predefined rules.
Types of firewalls:
Network-based firewalls (NIDS): Monitor traffic at planned points within the network.
Host-based firewalls (HIDS): Run on individual hosts, monitoring incoming and outgoing packets.
Firewalls prevent unauthorized access and filter traffic.
Intrusion Detection Systems (IDS): The Watchful Guardians
IDS passively observe network activity and alert incident responders.
Types of IDS:
Network IDS (NIDS): Monitor traffic from all devices on the network.
Host IDS (HIDS): Monitor specific hosts or devices.
IDS detects anomalies, policy violations, and potential attacks.
3. Encryption and Secure Communication Protocols
Encryption: Shielding Your Data
Encryption transforms plaintext into ciphertext using keys.
Symmetric encryption: Uses a single key for both encryption and decryption.
Asymmetric encryption: More secure, involving public and private keys.
Encryption protocols (e.g., TLS/SSL) ensure confidentiality during data transmission.
Remember, network security is an ongoing process. Regular updates, patches, and user awareness play a crucial role in maintaining a robust defense against cyber threats. Stay vigilant, and keep your digital fortress secure! 🔒🌐✨
Troubleshooting and Maintenance: A Comprehensive Guide
In the dynamic world of networking, maintaining optimal performance and swiftly resolving issues is crucial. Whether you’re an IT professional, a network administrator, or a curious learner, understanding the intricacies of troubleshooting and preventive maintenance is essential. In this blog post, we’ll explore key methodologies, common network problems, and preventive measures to keep your network running smoothly.
1. Network Troubleshooting Methodologies
Top-Down Approach
The top-down approach involves systematically analyzing network issues from a high-level perspective down to specific details. Here are the steps:
Define the Problem:
Gather information about the symptoms, affected users, and the scope of the issue.
Understand the impact on business operations.
Gather Detailed Information:
Collect data on network configuration, recent changes, and user reports.
Use monitoring tools to track performance metrics.
Probable Cause Analysis:
Identify potential causes based on the symptoms.
Consider hardware failures, misconfigurations, or external factors.
Plan for Resolution:
Devise a step-by-step plan to address the issue.
Prioritize critical tasks and allocate resources.
Implement the Plan:
Execute the planned steps, such as reconfiguring devices or replacing faulty components.
Monitor progress and adjust as needed.
Observe Results:
Verify whether the issue is resolved.
Measure performance improvements.
Repeat if Necessary:
If the problem persists, revisit the process and refine your approach.
Bottom-Up Approach
The bottom-up approach focuses on specific components and gradually builds a holistic view of the network. Here’s how it works:
Start with the Basics:
Check physical connections, power sources, and hardware status.
Ensure cables are securely plugged in and devices are powered on.
Use Diagnostic Tools:
Run commands like ipconfig, ping, and tracert to test connectivity.
Analyze network traffic using packet sniffers.
Inspect Network Devices:
Review router and switch configurations.
Look for errors, dropped packets, or unusual behavior.
Check DNS and DHCP:
Verify DNS resolution and DHCP lease assignments.
Address any issues related to name resolution.
Examine Security Settings:
Review firewall rules, access control lists (ACLs), and security policies.
Ensure proper authentication and authorization.
Collaborate with ISP:
If external connectivity is affected, contact your internet service provider (ISP).
Confirm service availability and troubleshoot connectivity.
Document Findings:
Maintain detailed records of your troubleshooting steps.
Share insights with colleagues for collective learning.
Divide and Conquer Approach
This method involves breaking down complex issues into smaller parts:
Isolate Segments:
Divide the network into segments (LAN, WAN, wireless, etc.).
Determine which segment is affected.
Test Each Segment:
Focus on the problematic segment.
Test connectivity, performance, and configuration.
Narrow Down the Issue:
Identify the specific device or area causing the problem.
Mastering Network Design and Implementation: A Guide to Planning and Principles
Delve into the complex world of network design and implementation, where strategic planning and key principles play a crucial role in success. Understanding business needs and objectives is essential for creating a network infrastructure that meets requirements and ensures efficiency. Implementing robust security measures is paramount in safeguarding data and protecting against cyber threats. Explore the importance of optimising network performance and scalability, while also integrating cloud services for increased flexibility. Discover the role of automation and compliance with regulatory requirements in network design, along with effective management and monitoring for seamless operations. Master the art of network design and implementation with this comprehensive guide to success.
1. Introduction: Understanding the Importance of Network Design and Implementation
In delving into the realm of network design and implementation, one must grasp the intrinsic significance that these processes hold within the realm of modern business operations. The foundation of a successful network lies in meticulous planning and adherence to key principles that guide its development. By aligning the network design with the specific needs and objectives of the business, one can ensure a seamless integration that enhances overall efficiency and productivity. Furthermore, the implementation of robust security measures is paramount in safeguarding sensitive data and protecting against cyber threats. Optimising network performance and scalability is essential for accommodating the evolving demands of a dynamic business environment. Embracing cloud services in network design can unlock new possibilities for connectivity and resource allocation. Automation plays a pivotal role in streamlining network operations and reducing manual intervention, while ensuring compliance with regulatory requirements is non-negotiable. Effectively managing and monitoring network operations is crucial for identifying and resolving issues promptly. In conclusion, mastering network design and implementation is a multifaceted endeavour that demands attention to detail, strategic planning, and a forward-thinking approach to technology integration.
2. Key Principles of Network Planning for Success
When embarking on the journey of network design and implementation, it is crucial to understand the key principles that pave the way for success. By focusing on meticulous planning, businesses can ensure a robust and efficient network infrastructure that meets their current and future needs. From determining the right hardware and software components to establishing clear objectives and performance metrics, a well-thought-out plan is essential. Additionally, considering factors such as scalability, security, and compliance with regulatory requirements is paramount in creating a network that can support the organization's growth and protect its sensitive data. By adhering to these key principles, businesses can lay the foundation for a network that not only meets their needs today but also remains adaptable and secure in the face of evolving technologies and threats.
3. Identifying Business Needs and Objectives in Network Design
To ensure a successful network design and implementation, it is crucial to identify the specific business needs and objectives. Understanding the unique requirements of the organisation will guide the planning process and help in creating a network infrastructure that aligns with the overall goals. By conducting a thorough analysis of the business operations and future growth plans, network designers can tailor the network to support current demands while also allowing for scalability. This step is essential in determining the necessary hardware, software, and security measures needed to meet the organisation's objectives effectively. Moreover, by considering factors such as budget constraints and regulatory compliance, network designers can develop a comprehensive plan that addresses all aspects of the business requirements. Ultimately, aligning the network design with the business needs is key to achieving success in network implementation.
4. Implementing Security Measures in Network Infrastructure
When it comes to network design and implementation, security should be a top priority. Implementing robust security measures in your network infrastructure is essential to protect sensitive data and prevent cyber threats. From setting up firewalls and encryption protocols to regularly updating software and monitoring for suspicious activity, there are various steps you can take to enhance the security of your network. By investing in strong security measures, you can safeguard your business operations and build trust with customers. Remember, a secure network is a strong network, so make sure to prioritise security in your network design and implementation process.
5. Optimizing Network Performance and Scalability
In order to ensure the smooth functioning of a network, optimizing performance and scalability is crucial. By constantly monitoring and evaluating the network infrastructure, potential bottlenecks and inefficiencies can be identified and addressed promptly. Implementing load balancing techniques and prioritizing critical traffic can help in maximizing network efficiency. Scalability should also be considered from the outset, allowing for seamless expansion as the business grows. Utilizing advanced technologies such as virtualization and software-defined networking can further enhance scalability and adaptability. Regular performance assessments and capacity planning are essential to keep the network running at peak performance levels. By focusing on optimization and scalability, businesses can future-proof their network infrastructure and ensure uninterrupted operations.
6. Integrating Cloud Services in Network Design
Integrating Cloud Services in Network Design is a crucial aspect that can significantly enhance the efficiency and flexibility of a network infrastructure. By incorporating cloud-based solutions, organisations can scale their operations seamlessly, reduce capital expenditure on hardware, and improve accessibility to data and applications. This integration requires careful consideration of factors such as security protocols, data management processes, and network performance. Implementing a hybrid cloud approach, for example, can provide the best of both worlds by combining the benefits of public and private cloud services. Additionally, utilising Software as a Service (SaaS) or Infrastructure as a Service (IaaS) models can further optimise resource allocation and streamline network operations. Ultimately, integrating cloud services in network design is essential for modern businesses looking to stay competitive and agile in today's digital landscape.
7. The Role of Automation in Network Implementation
Automation plays a crucial role in the successful implementation of network design. By automating routine tasks such as configuration management and troubleshooting, organisations can streamline operations, reduce human error, and increase efficiency. Automation tools can also help in maintaining consistency across network devices and ensure faster deployment of new services. With the growing complexity of networks and the increasing demand for agility, automation has become essential for modern network infrastructure. Implementing automation not only saves time and resources but also allows IT teams to focus on strategic initiatives rather than repetitive tasks. By embracing automation in network implementation, businesses can stay ahead of the curve and adapt quickly to changing technology landscapes. In conclusion, integrating automation into network design is a key component of mastering network implementation and ensuring long-term success in today's digital age.
8. Ensuring Compliance with Regulatory Requirements in Network Design
In order to guarantee a successful network design and implementation, it is crucial to ensure compliance with regulatory requirements. Adhering to industry standards and government regulations not only protects the network from potential security threats but also helps in maintaining the integrity of the entire system. By staying up-to-date with legal frameworks and data protection laws, businesses can avoid costly penalties and reputation damage. Implementing robust security measures and encryption protocols is essential to meet compliance standards and safeguard sensitive information. Regular audits and assessments should be conducted to identify any gaps in compliance and address them promptly. Ultimately, by prioritising regulatory compliance in network design, organisations can build a strong foundation for a secure and resilient network infrastructure.
9. Managing and Monitoring Network Operations Effectively
In order to ensure the smooth and efficient functioning of a network, it is crucial to focus on managing and monitoring network operations effectively. This involves the continuous monitoring of network performance, identifying potential issues, and implementing timely solutions to prevent any disruptions. By establishing robust monitoring systems and utilising advanced management tools, network administrators can proactively address any network-related concerns and maintain optimal performance levels. Additionally, regular performance evaluations and audits help in identifying areas for improvement and enhancing overall network efficiency. Through meticulous management and vigilant monitoring practices, organisations can uphold the integrity and reliability of their network infrastructure, ensuring seamless connectivity and uninterrupted operations for all users.
10. Conclusion: Mastering Network Design and Implementation - A Comprehensive Guide to Success
In the realm of network design and implementation, achieving success requires a meticulous approach and adherence to key principles. By understanding the importance of planning and incorporating the specific needs and objectives of the business, a solid foundation can be laid. Security measures must be integrated into the network infrastructure to safeguard against potential threats. Optimizing network performance and scalability is essential for meeting the growing demands of a dynamic business environment. Embracing cloud services in network design can enhance flexibility and efficiency. Automation plays a crucial role in streamlining implementation processes. Ensuring compliance with regulatory requirements is non-negotiable in today's data-driven landscape. Effective management and monitoring of network operations are vital for maintaining efficiency and security. By following these guidelines, one can truly master network design and implementation, paving the way for sustainable success.
Network Services and Applications** - DNS, DHCP, FTP, and HTTP - Email and web services - Remote access and VPNs
Network services and applications are fundamental components of modern networking infrastructure, facilitating communication, data transmission, and access to resources across the digital landscape. This article delves into the workings of key network services such as DNS, DHCP, FTP, and HTTP, shedding light on their functionalities and significance in enabling seamless connectivity. Additionally, it explores the realm of email and web services, discussing their pivotal roles in communication and information dissemination. Moreover, remote access technologies and the secure connectivity offered by Virtual Private Networks (VPNs) are examined, emphasizing their importance in today's interconnected world. Join us on a journey through the intricate web of network services and applications that form the backbone of our digital interactions.
**Introduction to Network Services and Applications**
Network services and applications are like the unsung heroes of the internet world. They work behind the scenes, making sure everything runs smoothly so you can binge-watch cat videos without interruption.
**Understanding Network Services**
Network services are like the glue that holds the internet together. They help devices communicate with each other by providing essential functions such as routing data, translating domain names into IP addresses (DNS), and assigning IP addresses dynamically (DHCP).
**Importance of Network Applications**
Network applications are the cool kids on the block – they're the programs and services that make the internet fun and functional. From sending emails to browsing websites, network applications help us stay connected and get things done.
**Domain Name System (DNS) and Dynamic Host Configuration Protocol (DHCP)**
Ever wonder how your browser magically knows where to find that hilarious cat meme? Thank DNS for translating user-friendly domain names like "catvideos.com" into computer-friendly IP addresses.
DHCP, on the other hand, plays the role of a friendly neighborhood IP address provider, ensuring that every device on the network gets its unique address without causing a digital traffic jam.
**File Transfer Protocol (FTP) and Hypertext Transfer Protocol (HTTP)**
FTP is like your trusty old file courier, helping you upload and download files from servers with ease. It's the go-to protocol for transferring large files securely across the internet.
HTTP is the backbone of the World Wide Web, allowing your browser to fetch and display web pages from servers. It's the reason you can binge-watch cat videos (yes, we're back to cats) and online shop to your heart's content.
So next time you're browsing the web, sending an email, or downloading a file, remember the unsung heroes – network services and applications – working tirelessly in the background to make it all happen.**Network Services and Applications**
Email Services in Networking
Role of Email in Communication
Email, the unsung hero of digital communication! Whether you're sending work memos, cat videos, or just checking in with your grandma, email keeps us connected in this wild digital world.
Email Protocols and Standards
Think of email protocols and standards like the rules of the email game. SMTP (Simple Mail Transfer Protocol) handles outgoing mail, while POP (Post Office Protocol) and IMAP (Internet Message Access Protocol) help you fetch and manage your incoming messages.
---
Web Services and their Role in Networks
Introduction to Web Services
Ah, the magical world of web services! They're like the invisible helpers behind the websites we love. From fetching data to sending forms, web services make the internet a more interactive and dynamic place.
Common Web Technologies
HTML, CSS, JavaScript—these are the cool kids of web technologies. HTML structures your content, CSS makes it look pretty, and JavaScript adds interactivity. Together, they create the web experiences we can't live without.
---
Remote Access Technologies
Types of Remote Access
Remote access is like having a secret tunnel to your work computer from anywhere in the world. Whether it's through VPNs, remote desktop software, or good old SSH, remote access lets you work from your couch or a tropical beach (if you're lucky).
Benefits and Challenges of Remote Access
Working in your PJs? That's a remote access perk! But watch out for security risks and the occasional Wi-Fi dropout. Remote access gives you freedom, but it's not without its quirks.
---
Virtual Private Networks (VPNs) for Secure Connectivity
Understanding VPNs
VPNs are like digital invisibility cloaks that keep your online activities safe from prying eyes. They encrypt your data, hide your IP address, and let you browse the internet privately—even when you're sipping coffee at a sketchy airport hotspot.
Securing Data with VPNs
Hackers and data thieves? Not today, cyber villains! VPNs create a secure tunnel for your data to travel through, making sure your sensitive info stays safe and sound. It's like having a bouncer at the digital door of your online activities.In conclusion, network services and applications play a crucial role in shaping the way we connect, communicate, and collaborate in the digital age. By understanding the intricacies of DNS, DHCP, FTP, HTTP, email services, web services, remote access technologies, and VPNs, individuals and organizations can harness the power of networking to enhance productivity, efficiency, and security. As technology continues to evolve, mastering these foundational elements will be key to navigating the complexities of the interconnected world. Embrace the possibilities that network services and applications offer, and pave the way for a seamless and secure digital future.
```html
Frequently Asked Questions (FAQ)
1. What is the role of DNS in networking?
2. How does DHCP simplify IP address management in a network?
3. Why are FTP and HTTP important for file transfer and web browsing?
4. How do VPNs ensure secure connectivity for remote access?
We'll start our
journey by explaining how the Internet is like a big road that connects
computers all over the world. Just like a road helps cars get from one place to
another, the Internet helps information travel between devices. But how does
this all happen? That's where routers and Wi-Fi technologies come into play,
acting as the backbone of this digital highway.
Imagine the Internet
as a massive superhighway with lanes connecting every computer, phone, and
tablet together. Routers are like the traffic cops of this superhighway, making
sure data reaches its destination without getting lost. They help direct
information traffic efficiently, ensuring that your messages, videos, and
pictures arrive where they need to go.
Now, let's dive deeper
into the world of routers and Wi-Fi technologies to understand how they keep
this Internet superhighway running smoothly.
Routers: The Traffic Cops of the Internet
In this part, we'll
learn about routers and how they act like traffic cops, directing data where it
needs to go.
What is a Router?
We'll explain what a
router is in simple terms and how it connects to your devices at home. Think of
a router as a smart device that helps your computer or phone talk to other
devices on the Internet. It's like a traffic cop that decides which data goes where,
making sure everything gets to its destination quickly and safely.
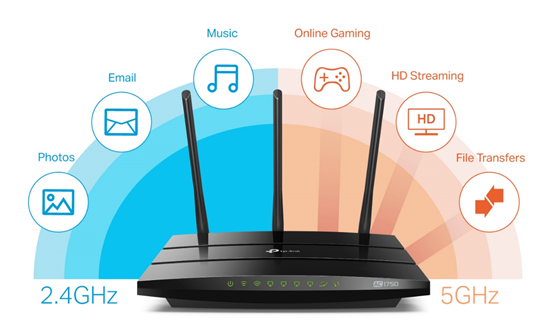
Types of Routers
We'll look at
different types of routers and how they're used in different situations. Some
routers are big and powerful, handling lots of data for a whole building or
even a neighborhood. Others are smaller and perfect for homes, making sure your
devices can all connect to the Internet without any problems. No matter the
size, routers are essential for keeping the Internet superhighway running
smoothly.
Check out the top routers and tech for 2023 to revamp your Wi-Fi
and enhance your connectivity! [insert link] #technology #innovation #wifi
Here, we'll discover
how Wi-Fi lets us use the Internet without any wires and the different kinds of
Wi-Fi you might find.
Understanding Wi-Fi
We'll explain what
Wi-Fi is and how it lets us connect to the Internet wirelessly. Imagine Wi-Fi
as invisible threads that carry information from your device to the Internet
and back. It's like magic!
Wi-Fi vs. Ethernet
We'll compare Wi-Fi
with Ethernet, which is like a wired Internet connection, and see how they are
different. While Wi-Fi lets you move around freely with your device, Ethernet
keeps you connected through a cable. Both have their advantages, so it's cool
to have options!
Ethernet: The Wired Web
In this section, we'll
talk about Ethernet cables and how they help connect devices to the Internet
with a wire.
What is Ethernet?
Ethernet is like a
virtual highway that allows computers to communicate with each other. It's a
type of cable that connects your computer to the Internet, just like roads
connect different places.
How Ethernet Works
When you plug an
Ethernet cable into your computer, it's like giving it a direct path to the
Internet. This wired connection is often faster and more reliable than Wi-Fi
because there's no chance of interference from other devices or walls blocking
the signal.
IP Addressing: The Address Book of the Internet
In this section, we'll
dive into the world of IP addressing and discover how it serves as the address
book of the Internet, ensuring that data reaches the right destination.
Imagine your device on
the Internet is like a house, and an IP address is its unique address that
tells other devices where to send data. Just like how your home address helps
the mailman deliver letters to your house, an IP address helps data find its
way to your device on the Internet.
Why IP Addresses are Important
Every device connected
to the Internet needs an IP address to communicate with other devices. Without
an IP address, data wouldn't know where to go, just like how a letter without
an address wouldn't reach its intended recipient. IP addresses ensure that information
flows smoothly across the vast network of the Internet.
Common Networking Protocols: The Rules of the Road
Just like roads have
rules, the Internet has protocols. These protocols are like the guidelines that
help data travel safely and efficiently from one place to another on the web.
Let's take a closer look at these common networking protocols that play a
crucial role in keeping the Internet running smoothly.
What are Networking Protocols?
Networking protocols
are a set of rules that devices follow to communicate with each other over a
network. Think of them as the traffic laws of the Internet. These protocols
ensure that data is sent and received correctly, without getting lost or mixed
up along the way.
Examples of Networking Protocols
There are several
common networking protocols that you may have heard of before. One of the most
well-known protocols is TCP/IP, which stands for Transmission Control
Protocol/Internet Protocol. This protocol is like the main highway that data
travels on when you're browsing the web or sending emails.
Another important
protocol is HTTP, or Hypertext Transfer Protocol, which is used for loading web
pages in your browser. When you type a website address into your browser, HTTP
helps retrieve the information from that site and display it on your screen.
Other protocols, like
FTP (File Transfer Protocol) and SMTP (Simple Mail Transfer Protocol), are used
for transferring files and sending emails, respectively. Each protocol has its
own specific function and helps different types of data move around the
Internet efficiently.
Conclusion: Wrapping Up the Internet Journey
As we reach the end of
our Internet journey, let's take a moment to recap all the exciting things
we've learned about how the Internet works. From routers to Wi-Fi, Ethernet, IP
addressing, and networking protocols, each piece plays a crucial role in
keeping us connected to the vast world of information and communication.
Routers are like
traffic cops on the Internet superhighway, directing data packets to their
intended destinations. Just like how a traffic cop ensures smooth flow on the
roads, routers make sure that information reaches your devices quickly and
efficiently.
Wi-Fi, the Invisible Connection
Wi-Fi technologies
allow us to connect to the Internet without the need for physical wires. It's
like magic! With different types of Wi-Fi signals available, we can stay
connected from anywhere within the range of a Wi-Fi network.
Ethernet, the Reliable Wired Web
When it comes to
stability and speed, Ethernet cables provide a reliable connection to the
Internet. While Wi-Fi is convenient, Ethernet ensures a more robust and secure
link between devices, especially in situations where a wired connection is preferred.
IP Addressing, the Digital Home Address
Just like how your
home has an address, every device connected to the Internet has an IP address.
This unique identifier allows data to find its way to the correct destination,
ensuring that information is delivered accurately and securely.
Common Networking Protocols, the Rules of the Internet
Networking protocols
are like the rules of the road for the Internet. They define how data is
transmitted, received, and interpreted across networks, ensuring that communication
between devices is standardized and secure.
By understanding the
fundamental components of the Internet, from routers to Wi-Fi, Ethernet, IP
addressing, and networking protocols, you are equipped with the knowledge to
navigate the digital world confidently. So, as you continue your exploration of
the vast online landscape, remember the essential role each of these elements
plays in keeping us all connected.
Frequently Asked Questions (FAQs)
We'll answer some
common questions that kids might have about how the Internet works.
Why do we need routers?
Routers are like
traffic cops on the Internet superhighway. They help direct data from one place
to another, making sure it reaches the right destination. Without routers, our
data would get lost or take a long time to reach where it needs to go.
Can I use the Internet without Wi-Fi?
Absolutely! While
Wi-Fi is a popular way to connect to the Internet wirelessly, you can also use
a wired connection like Ethernet. Ethernet uses cables to connect your devices
to the Internet, providing a reliable and fast connection.
What happens if two devices have the same IP address?
If two devices on the
same network have the same IP address, it can cause a lot of confusion. Just
like how two houses can't have the same address, two devices can't have the
same IP address on a network. This can lead to data getting sent to the wrong
device or not reaching its intended destination at all.